
Pythonで正規表現を使うには
Pythonで正規表現を扱うの際に、便利な標準パッケージ「re」と呼ばれるものがあります。
これを使えば、文字列の中から特定のパターンを検索・置換・抽出などが簡単に行えます。
今回は以下の公式documentをもとに解説していきますが、このdocumentもかなりわかりやすくまとめられているので、参考にご覧ください。

正規表現について
正規表現を知っている方はここは飛ばしても大丈夫です。
基礎「.」「^」「$」「*」「+」
まずは、「.」「^」「$」「*」「+」の役割ついて学びましょう。
簡単にまとめると、
「.」は改行以外の任意の一文字をマッチさせる。
「^」は文字列の先頭にあるもの。
「$」は文字列の末尾にあるもの。
「*」は直前の文字を0回以上繰り返す。
「+」は直前の文字を1回以上繰り返す。
特に、*と+は最大多数をとるようにマッチさせます。(貪欲マッチ)
これだけではわかりづらいですか、具体例を見ていきましょう。
Pythonは、シンプルで読みやすい構文を特徴とする汎用プログラミング言語です。データ分析、機械学習、Web開発、AI、科学計算など幅広い分野で利用されています。豊富な標準ライブラリとパッケージにより、短いコードで効率的な開発が可能です。
この文から全文をマッチさせる方法を考えましょう。
全文をマッチさせる方法として、3つあると思います。1つ目は、同じ文を用意する。2つ目は、任意の一文字をマッチさせる「.」を文字列の長さ文用意する。3つ目は、直前の文字を0回(もしくは1回)以上繰り返す「*」「+」を使い、「.*」でマッチさせる。
そして、正規表現を扱っていくうえで.*が一般的です。
少し冗長的に書いてしまいましたが、伝えたいのは正規表現をうまく使うことで効率的にパターンを取り出せるということです。
次に、先頭の「Python」と末尾の「開発が可能です。」を取り出しましょう。
この答えは、「^Python」、「開発が可能です。$」です。特に、文字の位置が分かりくいと思いますが、先頭のマッチは先頭に、末尾のマッチは末尾に書きます。
(余談)正規表現の簡単な仕組み
ここで貪欲マッチを勉強しましたが、この時後ろのパターンまで貪欲マッチさせてしまうのか疑問に思いませんでしたか。
これは、.+のようなパターンを最大多数でとりながら、後ろのパターンとのマッチを同時に確認しているのです。そして、とりすぎた分もとに戻します。
「あいうえおかきくけこさしすせそ」という文字列に対して、”あいうえお.+さしすせそ”というパターンで取り出すとき、以下の流れのようになりま。
(.+)は「できるだけ多く文字を取ろう」とします。- しかし、その後に続くパターン(今回なら
さしすせそ)が マッチできるかどうか を同時に確認 - もし
(.+)が文字を取りすぎてしまうと、その後のさしすせそがマッチしなくなるので、
取りすぎた分を少しずつ戻して(backtracking)調整 - 結果、
(.+)は 「次のパターンにぶつかる直前まで」 の文字列を取ります。
「?」とは
前の正規表現では、最大多数をとる(貪欲マッチ)でしたが、?は0回か1回マッチさせます。(非貪欲マッチ)
つまり、直前の文字があってもなくても良いということです。
It is apple.There many apples.
この例文でappleとapplesを取り出したいとき、複数形のsはあってもなくてもよいですね。このとき、apples?とすることでうまくマッチします。
直前の繰り返し回数指定{m},{m,n}
直前の文字のm回繰り返しを指定するには{m}、m回からn回の範囲指定では{m,n}です。
aaabbbccdddd
この文字列中のa,b,c,dを取り出すには、a{3}、b{3}、c{2}、d{4}となります。
文字の集合[]の使い方
[]という記号を使うことで、使う文字の指定ができます。
数字のみは[0-9]、英語の小文字のみは[a-z]、英語の大文字のみは[A-Z]。反対に、数字をマッチさせたくないときは、^を使い[^0-9]となります。
また、.+*など特殊文字はこの中では、ただの文字として扱われます。
略記法
先ほどの数字のみ[0-9]と書きましたが、これは省略キーワード\dで表すことができます。
以下が略記法の一覧です。
| 書き方 | 意味 | 同等の略記法 |
|---|---|---|
[0-9] | 数字 | \d |
[A-Za-z] | 英字 | — |
[A-Za-z0-9_] | 英数字+アンダーバー | \w |
[^A-Za-z0-9_] | 英数字以外 | \W |
[^0-9] | 数字以外 | \D |
特殊文字を無効化\
[]や*などのマッチを文字として扱いたい場合、この文字の前に\を付けると文字として扱うことができます。
私の学んでいる言語は[Python]です
[Python]を取り出したいときは、[]という特殊文字を文字として扱う必要があります。
そのため、\[Python\]となります。
キャプチャ()とは
() で囲んだ部分が キャプチャグループとなり、グループとして中身を取り出すことができます。
使用する言語はPythonかRです。
PythonとRを取り出すために、([A-z]*)か([A-z])という正規表現を適用すると、”PythonかR”をそれぞれ取り出すことができます。その後、キャプチャグループを指定することで中身を取り出せます。
※後ほどまた解説します
応用:組み合わせ
「.*」「.+」 ー貪欲マッチ
貪欲マッチでできるだけ多くの文字列をマッチさせます。
私は「りんご」と「バナナ」と「みかん」を食べました。
上記の文に対して、「.*」という正規表現を当てはめてみると、「りんご」と「バナナ」と「みかん」となります。
「りんご」、「バナナ」、「みかん」のようにならないのは、*がなるべく多くの文字をマッチさせます。
「.*?」「.+?」 ー非貪欲マッチ
非貪欲マッチでできるだけ少ない文字列をマッチさせます。
私は「りんご」と「バナナ」と「みかん」を食べました。
上記の文に対して、「.*?」という正規表現を当てはめると、「りんご」、「バナナ」、「みかん」となります。
「.*」とは対照的に、?がなるべく最小の文字をマッチさせます。
「^.*$ 」—1行全体
一行全体の文字列をマッチさせます。
文字列の先頭と文字列の末尾へのマッチの間に、貪欲マッチを表す.*を使用することで、文字列全体をマッチさせることができる。
r’○○〇’で\を文字列として扱う
これはraw記法と呼ばれるのもので、\を特殊文字ではなくただの文字として扱います。
print('\n') #
print(r'\n') #\n上記のコードでわかる通り、r記法が使用されている場合、\がただの文字として出力されています。
これは正規表現としての特徴文字として扱いたいけど、Pythonの特殊文字として扱いたくない場合に役立ちます。
import re
text = "python is fun"
print(re.findall(r"\bis\b", text))
#['is']正規表現の略記法に単語の切れ目(空白など)を表す\bがあります。本来Pythonの文字列中では、\bはバックスペースとして認識されてしまいます。
これを解決するためにも、Pythonの本来の認識をエスケープする方法として先頭にrを付けます。
matchオブジェクトについて
reの返り値として、マッチした文字列を便利に扱うオブジェクトにmatchオブジェクトがあります。
具体的に考えるとmatchオブジェクトの便利さが分かると思います。
import re
text="使用する言語はPythonかRです。"
m=re.search("([A-z]*)か([A-z])",text)
print(m)
#<re.Match object; span=(7, 15), match='PythonかR'>re.searchについては一旦考えずに、”使用する言語はPythonかRです。”に対して、”([A-z]*)か([A-z])”のパターンでマッチさせています。結果は、<re.Match object; span=(7, 15), match=’PythonかR’>が返ってきます。
<re.Match object; span=(○, ○), match=’○○’>
span(○,○)でマッチした文字列の位置(開始と終了のインデックス)を示しています。
match=’○○’は実際にマッチしたものを表示しています。
<re.Match object; span=(7, 15), match=’PythonかR’>では、”PythonかR”が正しく取得しでき、その位置が7から15未満のインデックスだとわかります。
matchオブジェクトのメソッド
group系統のメソッド
group系統のメソッドを使うことでキャプチャグループを操作できます。
.group(n)
.group()だとマッチした文字列を返します。引数を入れることで、キャプチャグループを指定できます。
import re
text="使用する言語はPythonかRです。"
m=re.search("([A-z]*)か([A-z])",text)
print(m.group()) #PythonかR
print(m.group(0)) #PythonかR
print(m.group(1)) #Python
print(m.group(2)) #R.group(0)は.group()と同様に、マッチした文字列を取り出します。
.group(1)と.group(2)では、正規表現パターンの中身であるキャプチャグループを取り出しています。
.groups()
すべてのキャプチャグループをタプルで返します。
import re
text="使用する言語はPythonかRです。"
m=re.search("([A-z]*)か([A-z])",text)
print(m.groups()) #('Python', 'R')キャプチャグループPythonとRのタプルが返されます。
.groupdict()
名前付きグループを辞書で返します。
そのためには、先ほどのコードのキャプチャグループに対して名前を付ける必要があります。
名前の付け方は(?P<名前>パターン)という風に?P<名前>を付けます。
import re
text="使用する言語はPythonかRです。"
m=re.search("(?P<lang1>[A-z]*)か(?P<lang2>[A-z])",text)
print(m.groupdict())#{'lang1': 'Python', 'lang2': 'R'}キャプチャグループ1にはlang1、キャプチャグループ2にはlang2という名前を付け、それらの名前付きグループが出力されました。
位置系統のメソッド
グループごとの開始位置や終了位置の値を取得できます。
.start(n)
グループnの開始位置を取得できます。
import re
text="使用する言語はPythonかRです。"
m=re.search("([A-z]*)か([A-z])",text)
print(m.start()) #7
print(m.start(0)) #7
print(m.start(1)) #7
print(m.start(2)) #14.end(n)
グループnの終了位置を取得できます。
import re
text="使用する言語はPythonかRです。"
m=re.search("([A-z]*)か([A-z])",text)
print(m.end()) #15
print(m.end(0)) #15
print(m.end(1)) #13
print(m.end(2)) #15.span(n)
グループnのタプル(開始位置,終了位置)を取得できます。
import re
text="使用する言語はPythonかRです。"
m=re.search("([A-z]*)か([A-z])",text)
print(m.span()) #(7, 15)
print(m.span(0)) #(7, 15)
print(m.span(1)) #(7, 13)
print(m.span(2)) #(14, 15)reで使われる関数
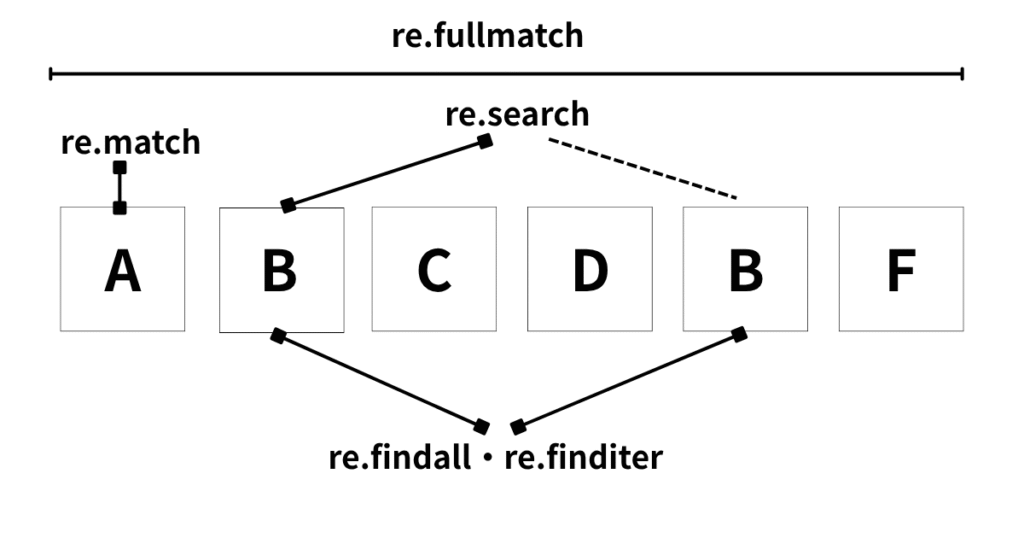
マッチング系
re.match(pattern,string)
patternが文字列の先頭にあれば、matchオブジェクトを返します。matchオブジェクトはmatchした文字列の開始位置、終了位置、グループなど便利に操作できるオブジェクトです。
import re
text="ある日の事でございます。御釈迦様《おしやかさま》は極楽の蓮池《はすいけ》のふちを、独りでぶらぶら御歩きになっていらっしゃいました。"
print(re.match("ある日",text).group())
#<re.Match object; span=(0, 3), match='ある日'>先頭の文字である「ある日」をre.matchでマッチさせています。
re.search(pattern,string)
文字列全体を検索し、最初にマッチした部分をmatchオブジェクトとして返します。
import re
text="ある日の事でございます。御釈迦様《おしやかさま》は極楽の蓮池《はすいけ》のふちを、独りでぶらぶら御歩きになっていらっしゃいました。池の中に咲いている蓮《はす》の花は、みんな玉のようにまっ白で、そのまん中にある金色《きんいろ》の蕊《ずい》からは、何とも云えない好《よ》い匂《におい》が、絶間《たえま》なくあたりへ溢《あふ》れて居ります。極楽は丁度朝なのでございましょう。"
print(re.search("極楽",text))
#<re.Match object; span=(25, 27), match='極楽'>極楽はこの文章の中で2回出現していますが、最初の極楽のみが返されています。
re.fullmatch(pattern,string)
文字列全体がパターンに一致するかチェックします。
import re
text="ある日の事でございます。"
print(re.fullmatch(".*",text))
#<re.Match object; span=(0, 12), match='ある日の事でございます。'>.*で全文をマッチさせることで、fullmatchでマッチさせています。
re.findall(pattern,string)
文字列全体を検索し、マッチした全ての部分文字列のリストを返します。
import re
text="ある日の事でございます。御釈迦様《おしやかさま》は極楽の蓮池《はすいけ》のふちを、独りでぶらぶら御歩きになっていらっしゃいました。"
print(re.findall("《(.*?)》",text))
#['おしやかさま', 'はすいけ']《(.*?)》という正規表現は漢字のフリガナをマッチさせ、それをグループ化させています。
re.finditer(pattern,string)
文字列全体を走査し、マッチごとの Match オブジェクトを返すイテレータを生成します。
import re
text="ある日の事でございます。御釈迦様《おしやかさま》は極楽の蓮池《はすいけ》のふちを、独りでぶらぶら御歩きになっていらっしゃいました。"
for i in re.finditer("《(.*?)》",text):
print(i)
#<re.Match object; span=(16, 24), match='《おしやかさま》'>
#<re.Match object; span=(30, 36), match='《はすいけ》'>matchオブジェクトを返すことにより、findallより詳しい情報を取得できています。
分割
re.split(pattern,string)
re.splitは指定の区切りパターンを使って文字列を分割します。
import re
text="するとその地獄の底に、犍陀多《かんだた》と云う男が一人、ほかの罪人と一しょに蠢《うごめ》いている姿が、御眼に止まりました。"
print(re.split("、",text))
#['するとその地獄の底に', '犍陀多《かんだた》と云う男が一人', 'ほかの罪人と一しょに蠢《うごめ》いている姿が', '御眼に止まりました。']「、」をもとに区切っています。今回では、.split(、)と同じ役目ですが、本来re.split()は正規表現パターンにより区切るという有利な点があります。
置換
re.sub(pattern, repl, string)
一致するパターンから第二引数で指定した文字列への置換を行います。
subnというものもあり、これはsubの返り値に置換回数も返します。
import re
text="そうしてそれだけの善い事をした報《むくい》には、出来るなら、この男を地獄から救い出してやろうと御考えになりました。"
res = re.sub(r"《.*?》", "", text)
print(res)
#そうしてそれだけの善い事をした報には、出来るなら、この男を地獄から救い出してやろうと御考えになりました。すべてのフリガナを””に置換しています。置換系の関数でよくある使い方で、指定の文字を””で置換することでその文字を削除することができます。
コンパイル
re.compile(pattern,flag)
事前に正規表現をコンパイルすることで、再利用を可能にします。
import re
pattern=re.compile("《(.*?)》")
text="ある日の事でございます。御釈迦様《おしやかさま》は極楽の蓮池《はすいけ》のふちを、独りでぶらぶら御歩きになっていらっしゃいました。"
print(pattern.findall(text))re.compileに正規表現を先に登録することで、引数をテキスト一つにしています。同じパターンで複数のテキストを用意している場合に役立ちます。
エスケープ
re.escape(pattern)
正規表現の特殊文字として意味のある文字をエスケープさせることで、ただの文字としてマッチさせます。
import re
text = "私はa+b*c?という式を書いた"
pattern = re.escape("a+b*c?")
result = re.search(pattern, text)
print(result)
#<re.Match object; span=(2, 8), match='a+b*c?'>本来+や*?は正規表現では意味を持ってしまいます。そのため、re.searchする前にエスケープ処理でただの文字として扱うことができます。
フラグ
頻出なフラグとして、re.MULTILINE とre.DOTALLは優先的に抑えておきたいフラグです。
re.MULTILINE
「^」と「$」を文字列の先頭・末尾ではなく、文章の行の先頭や末尾でのマッチに変わります。
import re
text = """一行目
二行目
三行目"""
pattern = r"^二行目$"
print(re.findall(pattern, text)) # フラグなし
print(re.findall(pattern, text, re.MULTILINE)) # フラグあり
re.DOTALL
.(ドット)が 改行 \n にもマッチ するようになります。
import re
text = """あいう
えお"""
pattern = r"あ.+お"
print(re.findall(pattern, text)) # フラグなし
print(re.findall(pattern, text, re.DOTALL)) # フラグあり
[] # 通常
['あいう\nえお'] # DOTALL.は本来改行以外の任意の一文字であるというのは、改行までの文字列に対する任意の一文字ということになります。そうすると、フラグなしの場合は、改行までに「お」がないため結果マッチしませんでした。
以下はご参考までにご覧ください
| フラグ | 説明 | よく使う場面 |
|---|---|---|
re.IGNORECASE / re.I | 大文字・小文字を区別せずにマッチ | "Python" と "python" を同一視したいとき |
re.MULTILINE / re.M | ^ と $ を各行の先頭・末尾に適用 | 複数行テキストの各行を処理したいとき |
re.DOTALL / re.S | . が改行にもマッチするようにする | 複数行にわたる文章を一気にマッチしたいとき |
re.VERBOSE / re.X | 空白やコメントを無視して見やすく書ける | 複雑な正規表現を整理して書きたいとき |
まとめ
本記事では、すべての機能について言及することはしませんでしたが、実際にPythonなどで正規表現を手を動かして学習していきましょう。



コメント